

ElevenLabs v3: Designing Voices with More Expression Than Ever
The world of AI voice generation just got a serious upgrade.
ElevenLabs has officially dropped v3 of their voice model, and it's a massive leap for creators, marketers, and anyone tinkering with audio automation.
ElevenLabs has released Eleven v3, a text-to-speech model that doesn't just read text — it performs it with human-like emotion, timing, and nuance that can genuinely fool trained audio professionals. This isn't merely an incremental update; it's a paradigm shift from mechanical speech synthesis to emotional performance that marks a new chapter in artificial intelligence.
Whether you're building characters for a game, personalizing customer support agents, or making your newsletter sound like David Attenborough — this update changes the game.
What’s New in Eleven V3?
Let’s cut straight to the magic. The Voice Design v3 model enables:
Design fictional characters, branded personas, or voice agents using natural language descriptions.
Dial in tone, pacing, inflections, age, gender — like you’re directing a real actor.
Yes, localized accents are here. That means regional nuance, not robotic “global English.”
Perfect for content, training modules, YouTube, podcasting, assistants — or your next viral Twitter audio meme.

How We’re Using It at iFlow.bot
We're already feeding Eleven v3 into our custom GPT agents to generate training modules, automated sales videos, and multi-language AI reps.
Here’s one use-case that’s making waves:
We designed a British-accented voice agent that pitches a SaaS product, answers objections with tone-adaptive responses, and hands over warm leads to human closers.
→ All powered by GPT + Eleven V3 + n8n automations.
This isn't sci-fi anymore. This is voice infrastructure for the age of automation.
What Makes Eleven v3 a Game-Changer
Since launching their Multilingual v2 model, ElevenLabs has seen voice AI adopted across professional film, game development, education, and accessibility sectors. However, the consistent limitation wasn't sound quality — it was expressiveness. More exaggerated emotions, conversational interruptions, and believable back-and-forth dialogue remained elusive challenges for the industry.
Eleven v3 addresses this gap head-on. Built from the ground up, it delivers voices that can sigh, whisper, laugh, and react naturally, producing speech that feels genuinely responsive and alive. The model represents a fundamental shift in how AI understands and processes human communication.
Core Technical Advantages
The new architecture behind v3 understands text context at a deeper level, enabling it to follow emotional cues, tone shifts, and speaker transitions more naturally than any previous model. This deeper comprehension allows for:
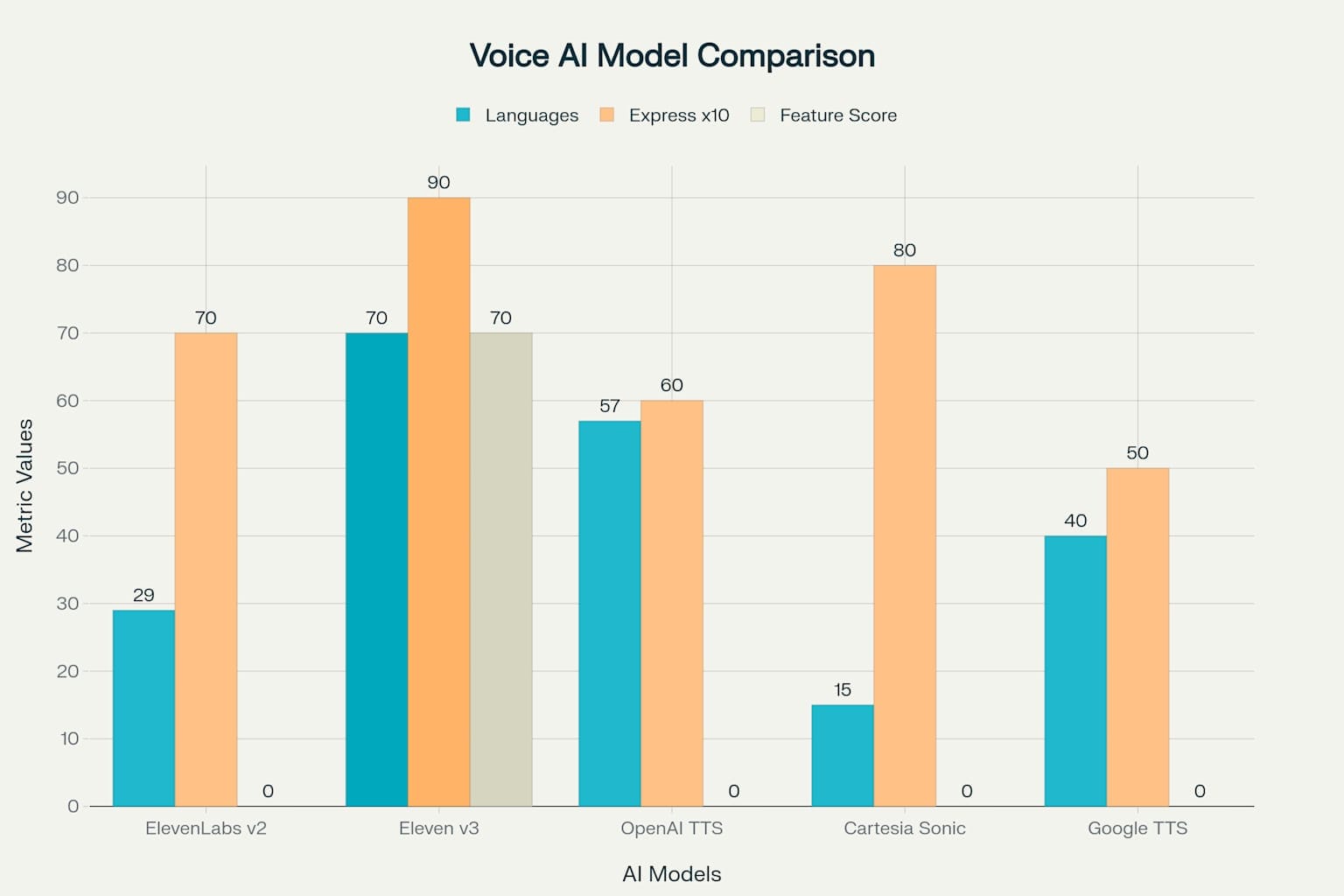
- Expanded Language Support: Jump from 29 to over 70 languages, increasing global population coverage from 60% to 90%
- Enhanced Emotional Range: Dynamic tone adjustments that respond to textual cues throughout speech
- Multi-Speaker Capabilities: Natural conversations with multiple voices, handling interruptions and emotional transitions
- Superior Audio Quality: Production-ready output suitable for professional media applications
Audio Tags: The Revolutionary Control System
Perhaps the most groundbreaking feature of Eleven v3 is its Audio Tags system — a revolutionary approach to controlling AI voice generation. These tags, formatted as lowercase words in square brackets, can be placed anywhere in your script to shape delivery in real-time.
Categories of Audio Tags
Emotional Control: Tags like [excited], [nervous], [frustrated], and [tired] set the emotional tone of the voice, allowing creators to inject genuine feelings into their content.
Performance Modulation: Volume and energy tags such as [whispers], [shouts], and [quietly] adjust the performance for scenes requiring specific atmospheric qualities.
Natural Reactions: Perhaps most impressively, reaction tags like [laughs], [sighs], [gasps], and [clears throat] add realistic, unscripted moments that bring authenticity to synthetic speech.
Accent and Style Control: Tags for different accents, from [American accent] to [British accent] to [Southern US accent], enable culturally rich speech without model swaps.
Practical Implementation
The beauty of audio tags lies in their simplicity and power. For example, you could prompt:"[whispers] Something's coming… [sighs] I can feel it."
Or combine multiple tags for complex emotional control:"[happily][shouts] We did it! [laughs]".
This level of granular control transforms content creation workflows. Audiobook producers can now direct emotional arcs with precision, game developers can create dynamic character interactions, and marketers can craft compelling narratives that resonate with specific emotional beats.
Content Creation and Media
Audiobook Production: Publishers can now create emotionally rich audiobooks with consistent character voices and precise emotional control. The ability to direct mood changes and character interactions through simple tags revolutionizes production workflows.
Gaming Industry: Game developers can create dynamic NPC interactions that respond naturally to player actions. Characters can express genuine emotions, handle interruptions, and maintain consistent personalities throughout extended gameplay sessions.
Film and Video: Independent filmmakers and large studios alike can leverage Eleven v3 for dubbing, narration, and character voice work, significantly reducing production costs while maintaining professional quality.
Business Applications
Customer Service: The technology enables more natural customer interactions, with AI agents capable of expressing empathy, understanding context, and responding with appropriate emotional tones.
E-Learning: Educational content becomes more engaging with expressive narration that can adapt to different learning contexts and maintain student attention.
Marketing and Advertising: Brands can create compelling audio content with precise emotional control, enabling more effective storytelling and customer engagement.
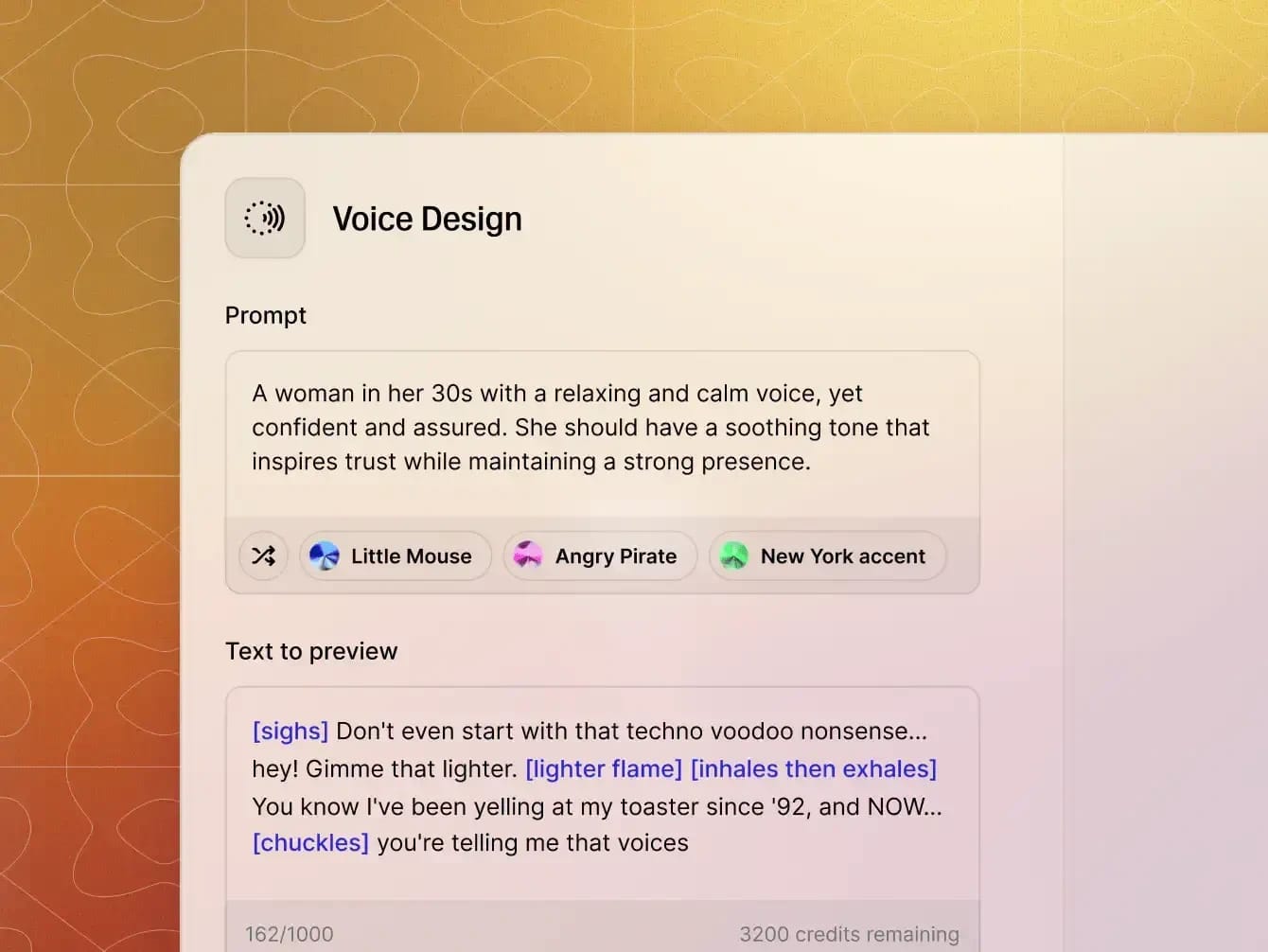
How to Design a Voice with ElevenLabs
Building your first character voice is ridiculously simple:
- Log into ElevenLabs
- Go to the Voice Library
- Click “Create or Clone a Voice”
- Choose “Voice Design”
- Enter your character prompt (e.g., “An upbeat Gen Z female mentor with Aussie accent”)
You’ll instantly generate a voice preview — and you can tweak it endlessly.
FAQs
Is Eleven v3 available on the free plan?
You can design voices on free and paid plans, but premium voices need a Pro subscription.
Can I use this for commercial voiceovers?
Yes — Eleven offers commercial usage rights depending on your plan.
How do [audio tags] work?
They let you adjust expression mid-sentence (like whispering or shouting). Great for storytelling.
Want More AI Tools Like This?
Join the iFlow.bot newsletter to get weekly drops on AI tools, automation tutorials, and behind-the-scenes workflows.
Built by creators, for creators.
See you in the library — Dave @ iFlow.bot













Discussion